Cluster Services
Check out these articles and learn more information about the WEBfactory 2010 Cluster Services.
WEBfactory 2010 Cluster Services is a expansion pack for WEBfactory 2010. It makes use of the Windows Server 2012 Cluster capabilities to provide a high availability and performance WEBfactory 2010 environment.
The package offers monitoring functionality and additional modules that can be shared easily and comfortably integrate into the Windows Cluster environment.
Monitoring modules observe whether all server applications, communication channels and sub-modules work as expected.
The additional cluster-modules integrate the monitoring in the Windows Cluster .
Not only the Windows Cluster service will be extended to monitoring objects, but also the Windows Cluster Administration allows access to the WEBfactory 2010 monitor parameters settings.
System Requirements
The WEBfactory 2010 Cluster Services package requires the following minimum conditions:
Failover Clusters consisting of Windows Server 2012/Windows Server 2012 R2 nodes; all Failover Cluster system requirements must be met.
All WEBfactory 2010 system requirements must be met;
All modules in a highly available system must be designed with redundancy, otherwise can endanger the availability of the system. We recommend to meet the additional conditions:
High availability database. Microsoft SQL Server 2014 Standard or Enterprise;
OPC Server. Perform OPC server also in a cluster network;
Identical hardware and software versions. We recommend that all redundant hardware (cluster node computers and additional hardware such as interface cards, etc.) to have identical components.
All Ewon by HMS Networks Services must run with a Domain User in a Cluster environment!
Cluster health monitoring and failure recovery
A Failover Cluster is, by default, configured to deliver high availability. This means that the cluster must have a minimal amount of down-time. This high availability is achieved through a complex monitoring and recovery process which is available on every Failover Cluster configuration. Ewon by HMS Networks Cluster Services relies on the high availability of the Failover Cluster to deliver the most reliable SCADA services.
The default Failover Cluster recovery settings are set up for common "worst case scenarios": the complete loss of a server through failures of non-redundant hardware or power. The goal of the Failover Cluster is to provide a quick-response solution to these kind of failures, by detecting the loss of a server and recovering on another server as fast as possible. This is possible thanks to the aggressive cluster health monitoring settings.
The aggressive health monitoring settings might not fit to all situations. For example, systems with augmented hardware resiliency (via redundant hardware) are less prone to hardware failures and complete server losses but might be affected by network communication failures. The cluster health monitoring settings can be tuned to a more relaxed state where the system has a greater tolerance to brief transient network issues. Of course, the longer time-outs will result in a slower recovery in case of hardware failures.
The heartbeat signal
The cluster health monitoring is based on a status signal called heartbeat. As the name suggests, this signal is sent periodically by all the servers in the cluster through a private network (heartbeat network - not accessible from outside the cluster). All the servers in the cluster receive all heartbeat signals thus are aware of the health of each other node in the cluster. If a cluster node fails in sending the expected control message - the heartbeat - in the predefined time frame, the recovery procedure begins on the other nodes of the cluster.
A crucial factor is the heartbeat network reliability, as a false alarm could trigger undesired recoveries which might damage data on shared network storage.
The heartbeat settings
The heartbeat communication between the cluster nodes can be tuned using two important parameters: Delay and Threshold.
The Delay defines the frequency at which heartbeat messages are sent between the cluster nodes. It represents the number of milliseconds between two consecutive heartbeats. The Delay parameter has two instances, one for nodes in the same subnet (SameSubnetDelay) and one for nodes in different subnets (CrossSubnetDelay).
The Threshold defines the number of skipped heartbeats before the cluster begins the recovery. Like the Delay parameter, the Threshold parameter has two instances, one for nodes in the same subnet (SameSubnetThreshold) and one for nodes in different subnets (CrossSubnetThreshold).
The default heartbeat settings for Windows Server 2012 and later is represented in the table below:
Parameter | Fast Failover (Default) |
|---|---|
SameSubnetDelay | 1000 milliseconds |
SameSubnetThreshold | 5 heartbeats |
CrossSubnetDelay | 1000 milliseconds |
CrossSubnetThreshold | 5 heartbeats |
The configuration of the cluster heartbeat settings can be done only though PowerShell, as they are considered advanced settings. Setting the heartbeat parameters can be done while the cluster is up and running, requires no down-time and will take effect immediately.
The heartbeat settings of a cluster can be viewed using the following PowerShell command:
get-cluster | fl *subnet*
Setting the Delay or Threshold parameters can be done using the following PowerShell commands:
(get-cluster).SameSubnetDelay = [value](get-cluster).SameSubnetThreshold = [value](get-cluster).CrossSubnetDelay = [value](get-cluster).CrossSubnetThreshold = [value]
Heartbeat traffic logs
When heartbeat signals are skipped, the Cluster.log is updated with the relevant logs. This is extremely useful for troubleshooting dropped heartbeat packets.
The amount of logs is dictated by the RouteHistoryLength setting, which has a default value of 10. This setting must be tuned in sync with the Delay and Threshold heartbeat parameters, so there is always enough logging available for troubleshooting. This setting can be set using the following PowerShell command:
(get-cluster).RouteHistoryLength = [value]
Cluster Configuration Examples
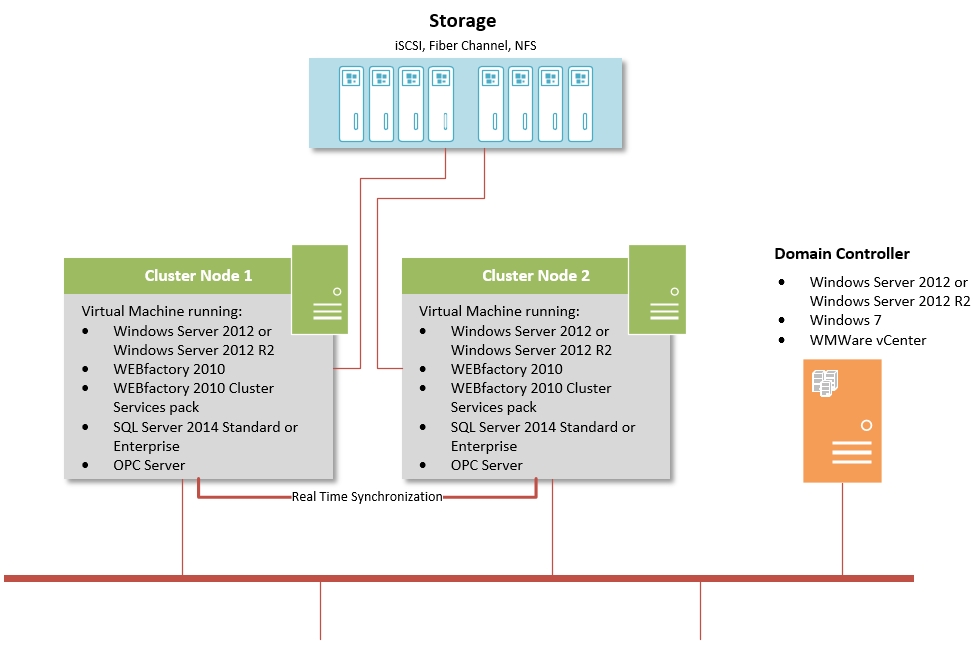
Failover Cluster with Microsoft Windows Server 2012 or Microsoft Windows Server 2012 R2
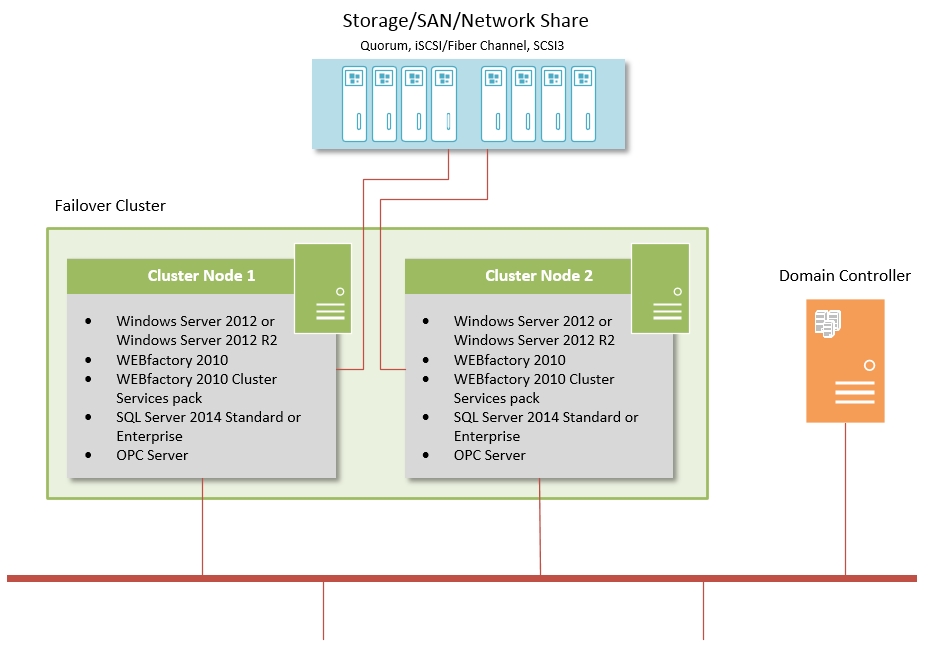
Highlights:
One virtual IP address to access the Windows Cluster/visualization IIS web server
Integration of Ewon by HMS Networks Cluster Services in the Windows Cluster monitoring (switchover to the other cluster node in case of errors, the monitoring is done by the Cluster itself)
Shared memory for SQL Failover Cluster
Expansion possibility by adding more nodes
Software on each node:
Microsoft Windows Server 2012 or Microsoft Windows Server 2012 R2, Standard or Datacenter editions
WEBfactory 2010
WEBfactory 2010 Cluster Services pack
SQL Server 2014 Standard or Enterprise editions
OPC Server
Failover Cluster with VMWare Standard/Essentials Plus
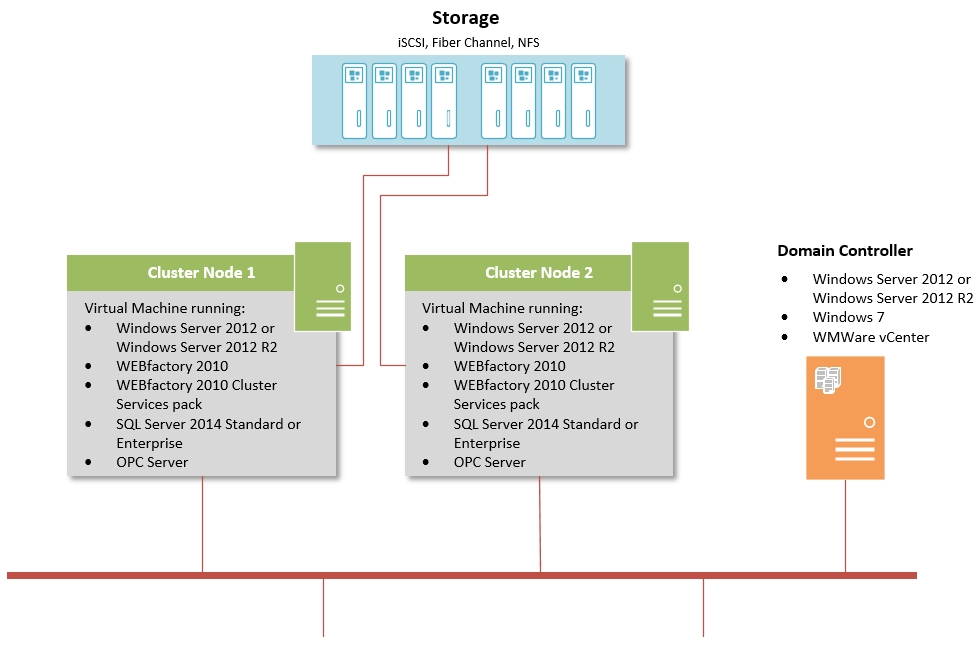
Failtolerance Cluster with VMWare Enterprise